
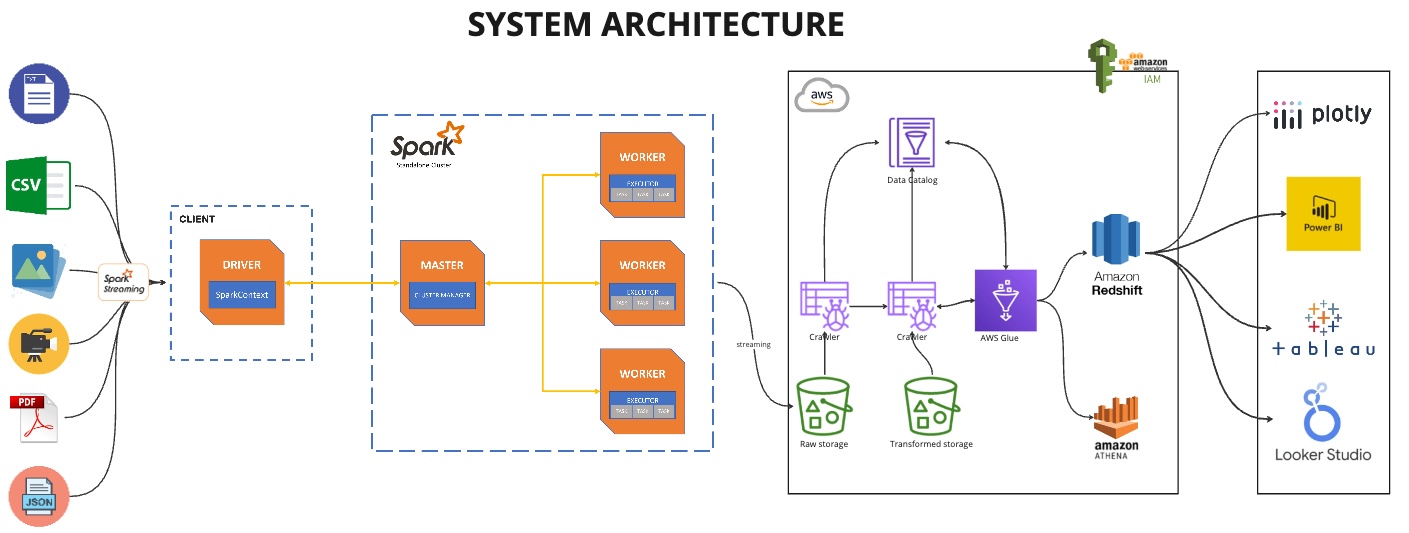
In the digital era, where data is likened to oil, the ability to efficiently process and analyze unstructured data in real-time is becoming increasingly crucial for businesses to maintain a competitive edge. The advent of technologies such as Apache Spark and cloud services like AWS has revolutionized data engineering, enabling the handling of diverse data types — text, images, videos, CSVs, JSON, and PDFs — across myriad datasets. This article delves into the intricacies of building real-time streaming pipelines for unstructured data, offering a roadmap for data engineers and IT professionals to navigate this complex landscape.
The Challenge of Unstructured Data
Unstructured data, lacking a predefined data model, represents the majority of data available in the digital universe today. From social media posts and digital images to emails and PDF documents, unstructured data is rich in information but complex to process and analyze due to its non-standardized format. The challenge lies not only in processing this data efficiently but also in doing so in real-time to extract valuable insights that can inform business decisions, enhance customer experiences, and drive innovation.

Use case: Job Posting Data
Real-time streaming pipelines have emerged as a powerful solution to the challenges posed by unstructured data. These pipelines enable continuous data processing, allowing businesses to analyze and act upon data as it is generated. Unlike batch processing, which processes data in chunks at scheduled times, real-time streaming provides instantaneous insights, a critical advantage in applications such as fraud detection, social media monitoring, and live customer support.
Job postings are inherently diverse and complex. They contain a mix of structured data (such as employment type, experience level, and location) and unstructured data (including job descriptions, requirements, and qualifications). The unstructured nature of much of this data makes it difficult to categorize and analyze using traditional data processing methods. Real-time streaming pipelines offer a solution, enabling the continuous analysis of job postings as they are published, providing immediate insights into trends, skills demand, and market needs.
In the competitive job market, both employers and job seekers benefit from immediate access to information. Real-time streaming pipelines can significantly enhance the job posting and application process in several ways:
- Instantaneous Job Posting Updates: Employers can update job postings in real time, and changes are immediately reflected across all platforms. This ensures that potential applicants have access to the most current information, including job descriptions, requirements, and application deadlines.
- Dynamic Applicant Matching: By analyzing job seeker profiles and behaviors in real time, companies can dynamically match candidates with new job postings as soon as they become available. This not only improves the candidate’s experience by presenting them with relevant opportunities instantly but also helps employers quickly identify and engage with potential hires.
- Real-Time Feedback and Analytics: Employers can receive immediate feedback on the number of views, applications, and interactions with a job posting. This data can be used to adjust recruitment strategies on the fly, such as modifying job descriptions or requirements to attract a broader pool of candidates.
- Enhanced Candidate Experience: Real-time communication channels can be integrated into the job application process, allowing for instant notifications, updates, and interactions between employers and candidates. This immediacy can improve the overall experience for job seekers, keeping them engaged and informed throughout the application process.
How feasible is this, you asked? Let’s look at these examples:
Example 1: Identifying Emerging Skills in Tech Industry
Scenario: A tech company is looking to stay ahead of the curve by identifying emerging skills and technologies in the software development sector. Traditional methods of analyzing job postings often result in lagging indicators, as the data becomes outdated by the time it is processed.
Solution: By implementing a real-time streaming pipeline, the company can analyze job postings from various tech job boards and company websites as they are published. Using natural language processing (NLP) techniques within the pipeline, the system can extract key skills and technologies mentioned in the unstructured text of job descriptions and requirements.
Outcome: The company identifies a rapid increase in demand for skills related to artificial intelligence (AI) and machine learning (ML), as well as a growing interest in Rust programming language. This insight allows them to quickly pivot, offering training sessions to their existing staff and adjusting their recruitment focus to attract talent with these emerging skills.
Example 2: Real-Time Labor Market Analysis for Educational Institutions
Scenario: An educational institution aims to align its curriculum with the current job market demands to improve employability outcomes for graduates. Traditional curriculum review processes are slow and often rely on outdated job market data.
Solution: By leveraging a real-time streaming pipeline to analyze job postings across various sectors, the institution can gain immediate insights into the skills and qualifications most frequently demanded by employers. This analysis includes parsing complex job descriptions and extracting information on required qualifications, preferred skills, and industry certifications.
Outcome: The institution notices a significant demand for digital marketing skills across multiple industries, including certifications in Google Analytics and AdWords. In response, they quickly develop and introduce a new digital marketing module into their business and marketing programs, ensuring their graduates are well-equipped for the current job market.
Example 3: Adaptive Recruitment Strategies in Competitive Markets
Scenario: A recruitment agency specializes in placing candidates in highly competitive sectors, such as finance and technology. They struggle to keep up with the rapidly changing job market, often relying on intuition rather than data to advise clients on recruitment strategies.
Solution: Implementing a real-time streaming pipeline allows the agency to continuously monitor and analyze job postings from a wide range of sources, including niche job boards and financial news outlets. The system uses text analytics to identify trends in job titles, required experience levels, and competitive salary ranges.
Outcome: The agency identifies a growing trend for roles in financial technology (fintech) startups, with a particular emphasis on cybersecurity expertise and compliance knowledge. Armed with this information, they advise their clients to highlight these skills in their job postings and offer competitive salaries to attract top talent. Additionally, they guide candidates to focus on these growing niches, enhancing their placement success rate.
Example 4: Global Talent Acquisition for Multinational Corporations
Scenario: A multinational corporation with operations across several countries needs to understand global talent trends to standardize and optimize its hiring practices. The diversity of job markets and the volume of data make it challenging to gather actionable insights.
Solution: A real-time streaming pipeline, equipped with the capability to process and analyze job postings in multiple languages, enables the corporation to monitor global job trends. Advanced analytics and machine learning models are used to categorize data by region, industry, and job function, providing a comprehensive view of global talent demands.
Outcome: The corporation discovers a high demand for project management professionals in its Asian markets, contrasting with a focus on creative roles in marketing within North American regions. This insight allows them to tailor their recruitment strategies and job postings to match the regional demands, improving recruitment efficiency and effectiveness.














Leave a comment